grep
全称 Global search Regular Expression and Printing,提取文本内容的整行,执行速度快,适合大篇幅文本信息处理。
grep家族1
2
3grep 默认的基础正则表达式
egrep 扩展正则表达式(相当于 grep -E)
fgrep 不支持正则表达式或者元字符,搜索字符串速度快
使用方法
语法: grep [options] "搜索条件(正则表达式)" file
-n 显示搜索结果处于原文件的行号
-v 取反,只显示不符合条件的行内容
-o 只显示被匹配到的字符串,而不是整行
-i 不区分大小写
-A num 显示匹配到的行,同时附加多显示该行后的num行
-B num 显示匹配到的行,同时附加多显示该行前的num行
-E 使用扩展正则表达式
sed
sed主要用于文本替换、删除。其工作模式一般为逐行处理,处理过程会产生处理空间、结果空间。处理过程如下:
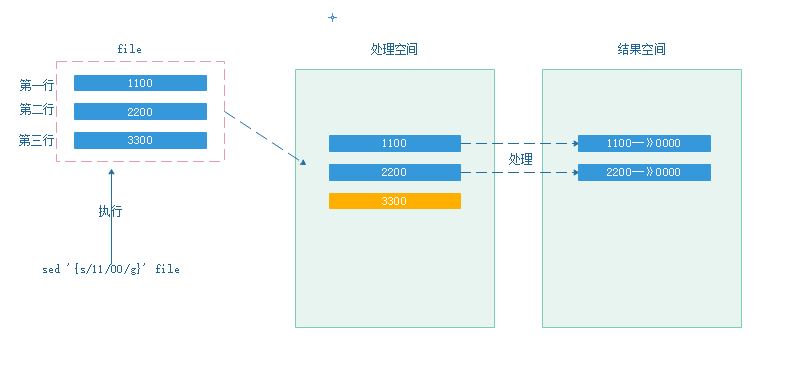
1
2
3默认情况下,不会文件本身进行操作(-i 表示改变文件,慎用)
默认情况下,sed会先读取文件所有行(可使用定界来确定文件读取的范围行)
若在模式空间中数据不符合匹配规则,则不作处理,直接原样输出
sed用法
语法: sed [options] ‘[定界/条件]{[动作]/[模式匹配空间]/[动作补充]}’ file
[options]
-n 静默模式,不输出模式空间的内容,一般拥有 p 操作
-e 指定一个sed命令中执行多个动作。格式:sed -e ‘1{p}’ -e ‘2{p}’ file
; 指定一个sed命令中执行多个动作,与-e效果一样。格式:sed ‘1{p};2{p}’ file
-i 直接修改原文件
-r 支持使用正则表达式
-f 从文件中读取处理脚本,并执行
定界/条件
1,7----第一到第七行
1,$ (1,)-----第一到最后一行
1,/正则/-----1,/^d/第一行到开头是d的那一行
/正则/,/正则/
/正则/-------/^d/匹配开头是d的所有行
动作
p 打印-----sed -n '1{p}' file
d 删除
a\text 在符合条件的行添加指定内容(可使用 \n 实现换行---多行添加)
i\text 在符合条件的行添加指定内容-----sed '1 i\22' file
c\text 符合条件的行替换为指定文本内容
r /path 在符合条件的文章追加指定文件内容---sed '/^root/r /file' /etc/passwd
w /path 将符合条件的行,保存到指定文件中;覆盖式输出,能自动创建文件
s/查找的内容/替换的内容/ &可以表示查到到的内容----sed '{s/root/&s/g}' passwd
补充标志位: /i 忽略大小写
/g 全局替换
awk
awk是一个非常强大文本处理工具,具有查找、切割、替换功能。程序执行分为三个部分:BEGIN段、主程序段、END段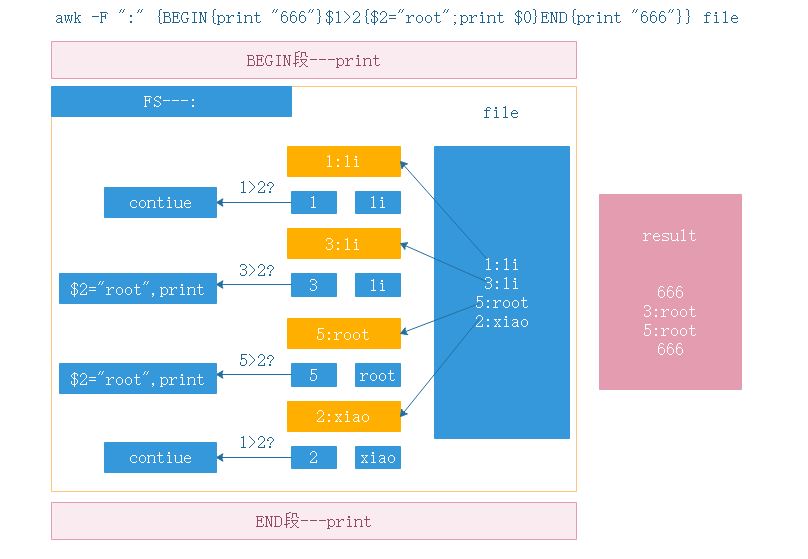
语法: awk -F “列分隔符” ‘BEGIN{} /模式空间–条件匹配|正则/{对每行的执行动作} END{}’
模式空间–匹配条件常用方法:
数值之间的比较: > < >= <= == != ($2>=2)
字符之间的比较:~ !~ 例:awk -F “:” ‘$2 ~ “li”{print $2}’ file
字符之间正则表达式: ~ !~ /正则|正则/
1 | 支持数值运算:++、--、+=、-=、*=、/=、%=、^=、**= |
内置变量理解
FS(field separator): 读取文件行时指定用的列分隔符(默认为空格,可自定义)
RS(Record separator): 读取文件指定的行分隔符(默认为换行符)
OFS(Output Filed Separetor): 输出时可以指定列字段分隔符,默认为空格
ORS(Output ROw Sepaertor): 输出时指定行分隔符,默认为换行符(/n)
NR(The number of input records): 显示当前正在处理的行编号
NF(Number of field): 统计每行分割列后的的总列数
FNR:当同时操作两个文件时,每一个文件的行号从头开始
ARGV:数组,保存命令本书这个字符串,如: awk '{print $0}' file—–ARGV[0]:awk; ARGV[1]:file
ARGC:统计ARGV的总个数
FILENAME: 当前正在处理的文件名称
ENVIRON:当前shell环境变量—-ENVIRON[“HOSTNAME”]
内置函数
split(string ,array,分隔符):对字符串进行切割,然后存放在array中1
2
3
4
5awk 'BEGIN{a="a,r,5 6h j";split(a,cc," ")}END{for(i in cc) print cc[i]}' file
输出:
a,r,5
6h
j
substr(string,start,length):从字符串第start位开始,截取长度为length的子字符串(字符串下标从1 开始)
system(“bash环境下的命令”):相当于搭建了一个shell工作环境
tolower(string): 将字符串全部转化为小写
toupper(string): 将字符串全部转化为大写
支持循环判断语句
if-else语句:
awk - F: ‘{ if($1 ~ /mail/ && $3>8) print $0 }’ /etc/passwd
while语句:
while (condition){statement1; statment2; ...}
for循环:
for ( variable assignment; condition; iteration process) { statement1, statement2, ...}
数组操作
定义一个数组:
awk 'BEGIN{avgs[0]="hulk";avgs[1]="natasha";avgs[2]="thor";avgs[3]=""print avgs[2]}'
判断一个数组元素是否存在:
可以使用语法 "if(下标 in 数组名)" ,从而判断数组中是否存在对应的元素。 可以使用 "!" 对条件进行取反
遍历数组:
for(i in array){.....}
对数组元素使用操作符:
如果我们操作的某个元素 是不存在的话,awk 会默认自动创建该元素,并将它的初始值设置为 0
awk 支持对 直接对数组中的 “空元素” 使用操作符。
可以使用管道操作符,但是只能使用一次,并且管道符后面的命令需要使用""引用起来
printf高级用法
使用格式:
printf "format1 [可选自定义字符] format2 format3" , item1, item2, item2 ...
常用字符表示:
%c: 显示第一个参数的第一个字符
%d, %i: 十进制整数;
%u: 无符号整数;
%e, %E: 科学计数法显示数值;
%f: 显示浮点数;
%g, %G: 以科学计数法的格式或浮点数的格式显示数值;
%s: 显示字符串;
%%: 显示%自身;
最后更新: 2019年10月10日 09:03
